
Problem Statement :
Used cars are priced based on their Brand, Manufacturer, Transmission type and etc etc. This is process is done by a professional who understands the condition and the right pricing scheme of the used cars form his/hers previous experiences. Our goal is to make a Model which can give an estimate of the price that should be intended for the used cars, based on historical data. The data is collected from Craigslist, Craigslist is the world’s largest collection of used vehicles for sale.
The source of the data can be found here.
About The Dataset
The dataset contains of 539759 rows and 25 dimensions. The Dimensions are mentioned below :
id : Unique Id of the car
url : Listing Url of the car
region : Craigslist Region
region_url : Region Url
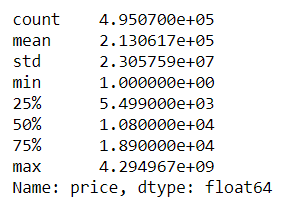
price : Price of the car
year : Year of Sale
manufacturer : Manufacturer of the car
model : Model of the car
condition : Condition the car is in
cylinders : Type of cylinder the car contains
fuel : Fuel Type of the car
odometer : No. of Miles the car traveled
title_status : Status of the vehicle
transmission : Transmission Type
vin : Vehicle Identification Number
drive : Drive Type
size : Size of the car
type : Type of the car
paint_color : Color of the car
image_url : Url of the image of the car
description : Description mentioned by the owner
county : County it belongs to
state : State where it is listed
lat : Latitude of Listing
long : Longitude of Listing
Data Analysis :
Column : ID
To check whether there is any duplicate ID present or not, if yes we can drop the columns of the duplicate ones. But fortunately, there were no Duplicate IDs present in the data.
Column : Price
As we check the price column, we can find 0 values and extreme values as min and max, obviously these values are outliers. Now According to many data available on google, we can say that the price of a used car can be max $150000 depending on cars like Ferarri, Lamborghini, but i would still keep it till $200000 as Max. And lowest being $100. Rest of the amounted rows will be dropped.
Column : Manufacturer
This column contains of different Manufacturers of the Car Brands, All the Values in this column has a not-null value with unique values of 43 count. Hence will be keeping all of them.
Column : Fuel
Talking about fuel, there are mainly 5 fuel types, excluding null values. We remove the rows of null fuel types.
Column : Transmission
This section contains 3 unique values, ‘automatic’, ‘manual’ and ‘other’. Also has null values which is dropped.
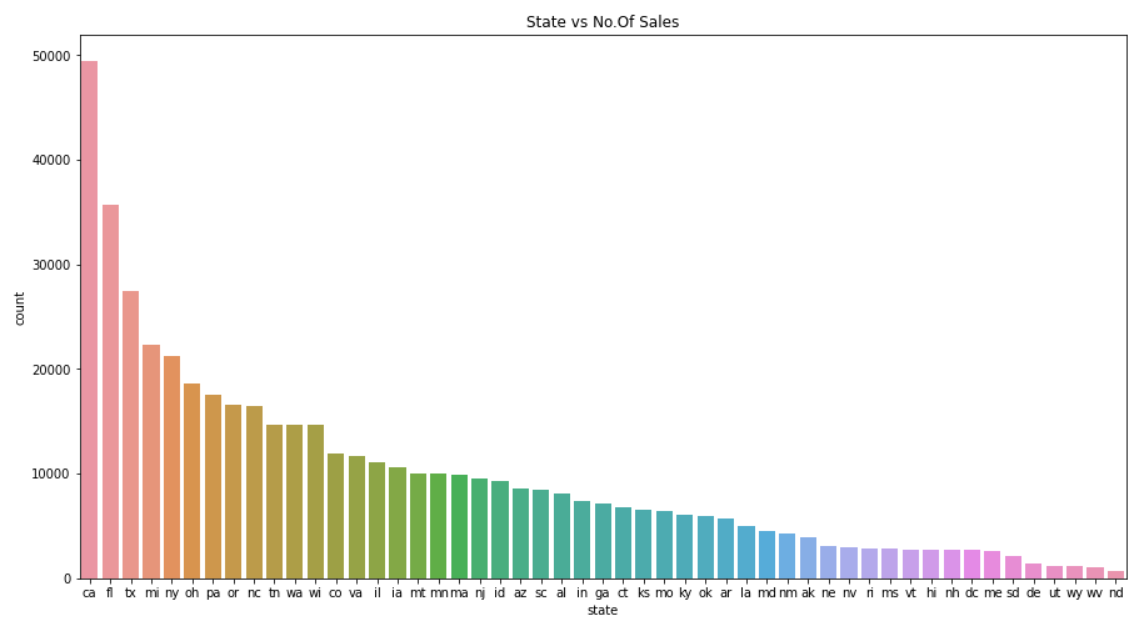
Column : State
There are around 51 unique state available, with no null values, hence we will be keeping them all.
Column : Year
Now, year is a very crucial column which might have some good quality of data. We need to be extra careful before dropping any column. There are around 112 unique years available, including 0 and null. The count of 0 and null values are less, hence can be safely removed.
Column : Odometer
This is a numerical value which states, the running distance of the car, with null values, we can remove them, or replace them with 0. Choice is yours.
Column : Drive, Type, Paint and Condition
These are the last 4 categorical columns, we can remove the null values, and keep the rest.
Apart from these columns rest of the columns will be dropped, you can choose to keep them. I choose these as it seems to be the most valued ones needed for prediction.
Data Visualization :
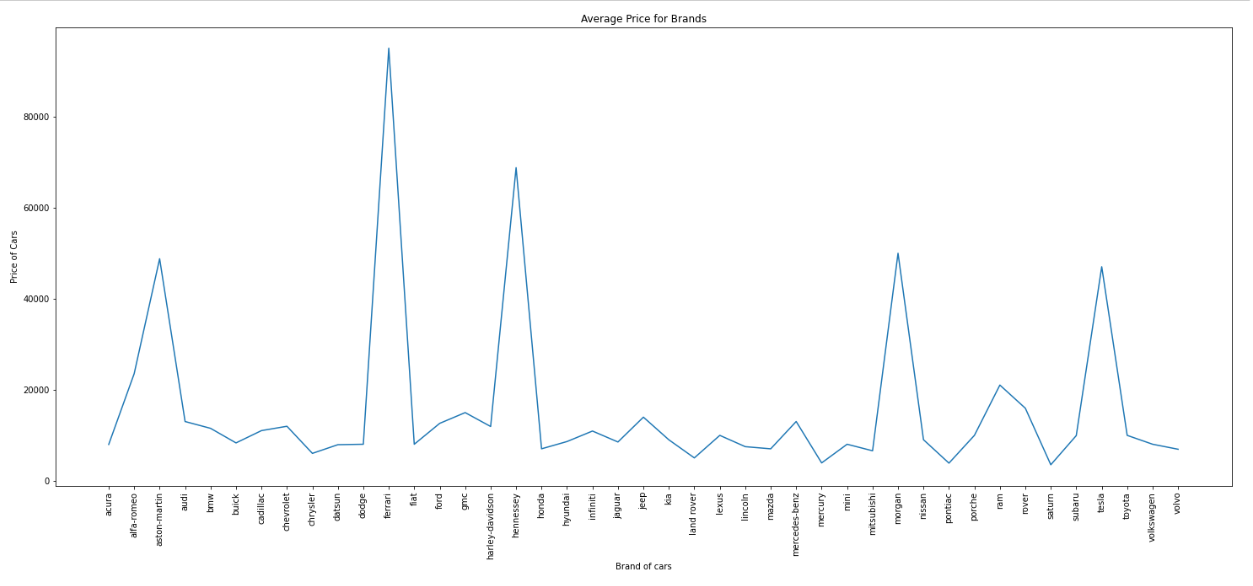
1. Plotting Price v/s Manufacturers
Average Price for Each type of Manufacturer
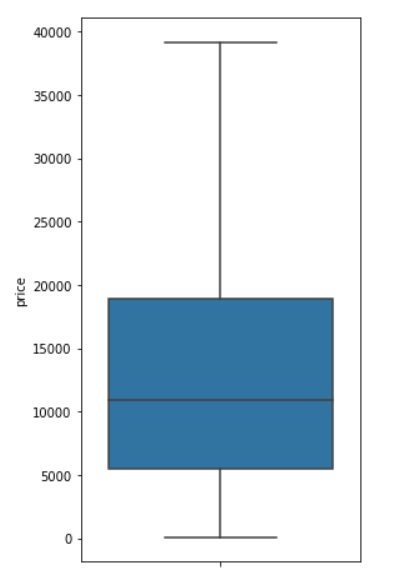
Checking top 20 Price Points used:
Feature Engineering :
Before getting into that, lets check the basic info of the data.
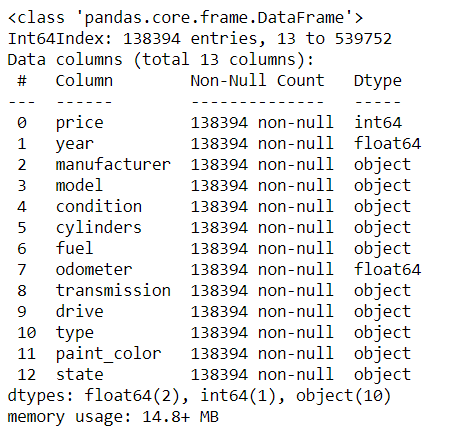
Splitting the data into Train and Test
We will split the data into Train and Test with a ratio of 80:20
Data Pre-Processing :
I have used 4 main types for Categorical data, as we can see we have most of them as categorical data. So below are the 4 used for categories.
- One-Hot Encoding : You can read about it in details here.
- Frequency Encoding : In this type of encoding, we can calculate the frequency of the category occurred in train data set, then replace them with the number of frequency of the value of each category occurred. Make sure not to include test data while frequency encoding to avoid data leakage.
- Value Encoding : This is a encoding type which i discovered to be helpful in my case, can be referred to as Label encoding but it’s slightly different, for example, my cylinders column has values like 4 cylinders, 6 cylinders which i replaced with 4 and 6 respectively. Which is not the case in Label Encoder as Label encoding is sequential.
- Ordinal Encoder : You can read about the difference of Ordinal and Label Encoding here.
Also for Numerical values, I Standardized them, with Standard Scalar in sklearn.
Once that is done, we are now ready to merge all out transformed data into a single frame for our models to train on it. We will use hstack form scipy.sparse to horizontally stack out features, make sure all are numpy arrays and are of same Row length.
Performance Metrics :
Will be using below 3 metrics for measuring the performance of our models. And those are : r2 score, relative error (mean absolute error)and rmse. I have linked each of them to a page where you can find sufficient info about them to read and understand.
ML Modeling:
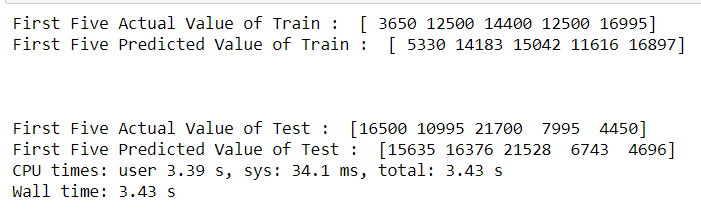
1. Linear Regression :
In statistics, linear regression is a linear approach to modeling the relationship between a scalar response (or dependent variable) and one or more explanatory variables (or independent variables). The case of one explanatory variable is called simple linear regression. (Source:Wikipedia)
Results — After Training the model :

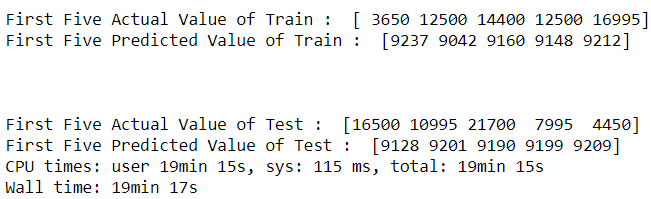
For people, who would not understand this, lets try to predict the first 5 values from both train and test using out trained model.
Actual v/s Predicted values :

As seen prediction isn’t that good.
Let’s Continue with other models.
2. Support Vector Regression :
In machine learning, support-vector machines (SVMs, also support-vector networks) are supervised learning models with associated learning algorithms that analyze data used for classification and regression analysis. Given a set of training examples, each marked as belonging to one or the other of two categories, an SVM training algorithm builds a model that assigns new examples to one category or the other, making it a non-probabilistic binary linear classifier (although methods such as Platt scaling exist to use SVM in a probabilistic classification setting). An SVM model is a representation of the examples as points in space, mapped so that the examples of the separate categories are divided by a clear gap that is as wide as possible. New examples are then mapped into that same space and predicted to belong to a category based on the side of the gap on which they fall. (Source : Wikipedia)
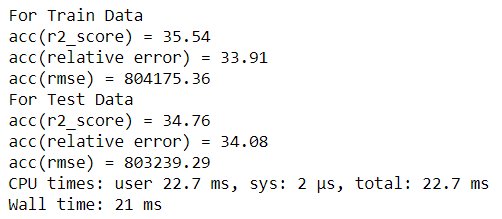
Results :

Actual v/s Predicted values :
3. Linear Support Vector Regression :
Linear Support Vector Regression.Similar to SVR with parameter kernel=’linear’, but implemented in terms of liblinear rather than libsvm, so it has more flexibility in the choice of penalties and loss functions and should scale better to large numbers of samples.
This class supports both dense and sparse input. (Source:sklearn)
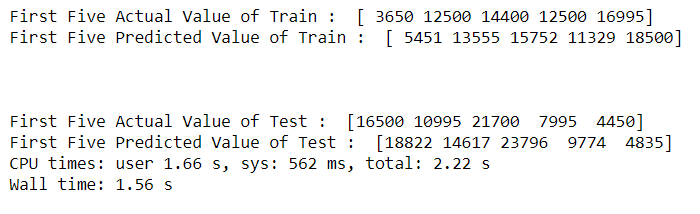
Results :
Actual v/s Predicted values :

4. MLP Regression :
Multi-layer Perceptron regressor. This model optimizes the squared-loss using LBFGS or stochastic gradient descent. MLPRegressor trains iteratively since at each time step the partial derivatives of the loss function with respect to the model parameters are computed to update the parameters.
It can also have a regularization term added to the loss function that shrinks model parameters to prevent overfitting.This implementation works with data represented as dense and sparse numpy arrays of floating point values. (Source:sklean)
Well i did a Hyper parameter tuning, of this one, you can also do the same. Identify the parameters which needs multiple values and train using GridSearch.
Results :


Actual v/s Predicted values :
5. SGD Regressor :
Linear model fitted by minimizing a regularized empirical loss with SGD SGD stands for Stochastic Gradient Descent: the gradient of the loss is estimated each sample at a time and the model is updated along the way with a decreasing strength schedule (aka learning rate). The regularizer is a penalty added to the loss function that shrinks model parameters towards the zero vector using either the squared euclidean norm L2 or the absolute norm L1 or a combination of both (Elastic Net). If the parameter update crosses the 0.0 value because of the regularizer, the update is truncated to 0.0 to allow for learning sparse models and achieve online feature selection. This implementation works with data represented as dense numpy arrays of floating point values for the features. (source:sklearn)
Results :
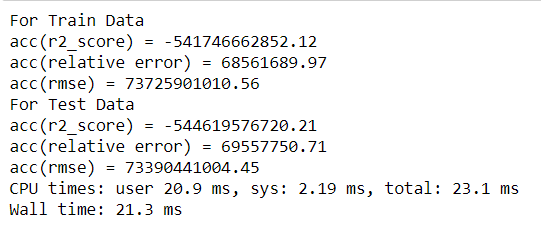
Actual v/s Predicted values :

The worst performance ever, well we can correct it by doing hyper parameter tuning and all, but for now i will leave it as it is.
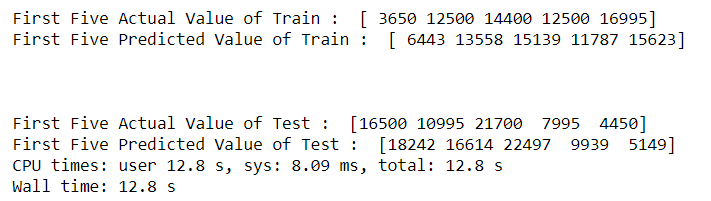
6. Decision Tree Regression :
Decision tree regression observes features of an object and trains a model in the structure of a tree to predict data in the future to produce meaningful continuous output. Continuous output means that the output/result is not discrete, i.e., it is not represented just by a discrete, known set of numbers or values.
Discrete output example: A weather prediction model that predicts whether or not there’ll be rain in a particular day.
Continuous output example: A profit prediction model that states the probable profit that can be generated from the sale of a product.(Source:GeeksForGeeks)
Results :

Actual v/s Predicted values :

If you see it is predicting the values of Train data perfectly and test data with no that much perfection, which means there is an overfit in the model. You can get rid of overfitting in many ways, regularization, depth of trees etc etc. Huge amount of Information is present in Google about it, just a search away.
7. XGB Regression :
XGBoost is an algorithm that has recently been dominating applied machine learning and Kaggle competitions for structured or tabular data. XGBoost is an implementation of gradient boosted decision trees designed for speed and performance.(Source:machinelearningmastery)
Results :
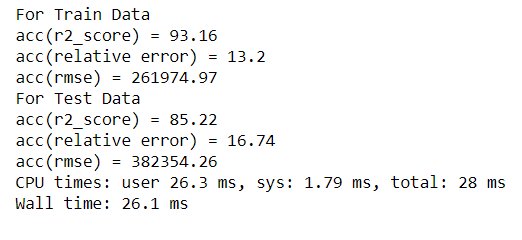
Actual v/s Predicted values :
Till now this has been the best one yet, with 85.22 % close range r2 accuracy.
8. Light GBM :
Light GBM is a gradient boosting framework that uses tree based learning algorithm. Light GBM grows tree vertically while other algorithm grows trees horizontally meaning that Light GBM grows tree leaf-wise while other algorithm grows level-wise. It will choose the leaf with max delta loss to grow. When growing the same leaf, Leaf-wise algorithm can reduce more loss than a level-wise algorithm. (Source:Medium)
Results :

Actual v/s Predicted values :
So, these are the types of model I have used to do this estimation, there are many other regression models out there which u can grab your hands on.
So, Explore..
Summarizing the Results of the Models :

Conclusion :
- As we can see i have not fine tuned my models, that is for you to try on your own.
- The performances of the models can be increased, by hyper parameter tuning.
- There are so many other Regression models out there, you can try some other than these.
- Try various other feature engineering to transform data and use them in your model, and let me know if you find any better results.
- Try to use any of the columns which i dropped, to make prediction better.



We’re a gaggle of volunteers and starting a brand new scheme in our community.
Your website offered us with useful information to
work on. You have done a formidable job and our entire community
shall be thankful to you. adreamoftrains best website hosting
Could you please share. the code? I am newbie and would give me a good start to understand the problem and implement. the solution.
many thanks.