K nearest neighbors or KNN algorithm is non-parametric, lazy learning, supervised algorithm used for classification as well as regression. KNN is often used when searching for similar items, such as finding items similar to this one. The Algorithm suggests that you are one of them because you are close to your neighbors. Now, let’s begin the article ” KNN from Scratch“.
How does a KNN algorithm work?
To conduct grouping, the KNN algorithm uses a very basic method to perform classification. When a new example is tested, it searches at the training data and seeks the k training examples which are similar to the new test example. It then assigns to the test example of the most similar class label.
What does ‘K’ in the KNN algorithm represent?
K in KNN algorithm represents the number of nearest neighboring points that vote for a new class of test data. If k = 1, then test examples in the training set will be given the same label as the nearest example. If k = 5 is checked for the labels of the five closest classes and the label is assigned according to the majority of the voting.

ALGORITHM
- 1. Initialize the best value of K
- 2. Calculate the distance between test data and trained data using Euclidean distance or any other method
- 3. Check class categories of nearest neighbors and determine the type in which test input falls.
- 4. Classify the test data according to majority vote of nearest K dataset
KNN FROM SCRATCH: MANUAL GUIDE
Let’s consider an example of height and weight
The given dataset is about the height and weight of the customer with the respective t-shirt size where M represents the medium size and L represents the large size. Now we need to predict the t-shirt size for the new customer with a height of 169 cm and weight as 69 kg.
| Height | Weight | T-Shirt Size |
|---|---|---|
| 150 | 51 | M |
| 158 | 51 | M |
| 158 | 53 | M |
| 158 | 55 | M |
| 159 | 55 | M |
| 159 | 56 | M |
| 160 | 57 | M |
| 160 | 58 | M |
| 160 | 58 | M |
| 162 | 52 | L |
| 163 | 53 | L |
| 165 | 53 | L |
| 167 | 55 | L |
| 168 | 62 | L |
| 168 | 65 | L |
| 169 | 67 | L |
| 169 | 68 | L |
| 170 | 68 | L |
| 170 | 69 | L |
CALCULATION
Step 1: The initial step is to calculate the Euclidean distance between the existing points and new points. For example, the existing point is (4,5) and the new point is (1, 1).
- So, P1 = (4,5) where x1 = 4 and y1 = 5
- P2 = (1,1) where x2 = 1 and y2 = 1
Now Euclidean distance = (x2- x1 )^2 +(y2- y1 )^2
= (1- 4 )2 +(1-5 )2 = 5
Step 2: Now, we need to choose the k value and select the closest k neighbors to the new item. So, in our case, K = 5, bold elements have the least Euclidean distance as compared with others.
| Height | Weight | T-Shirt Size | Distance |
|---|---|---|---|
| 150 | 51 | M | 26.17 |
| 158 | 51 | M | 21.09 |
| 158 | 53 | M | 19.41 |
| 158 | 55 | M | 17.80 |
| 159 | 55 | M | 17.20 |
| 159 | 56 | M | 16.40 |
| 160 | 57 | M | 15 |
| 160 | 58 | M | 14.21 |
| 160 | 58 | M | 14.21 |
| 162 | 52 | L | 18.38 |
| 163 | 53 | L | 16.49 |
| 165 | 53 | L | 16.49 |
| 167 | 55 | L | 14.14 |
| 168 | 62 | L | 7.01 |
| 168 | 65 | L | 4.12 |
| 169 | 67 | L | 2 |
| 169 | 68 | L | 2.23 |
| 170 | 68 | L | 1.41 |
| 170 | 69 | L | 10.04 |
Step 3: Since, K = 5, we have 5 t-shirts of size L. So a new customer with a height of 169 cm and a weight of 69 kg will fit into t-shirts of L size.
BEST K-VALUE IN KNN FROM SCRATCH
K in the KNN algorithm refers to the number of nearest data to be taken for the majority of votes in predicting the class of test data. Let’s take an example how value of K matters in KNN.

In the above figure, we can see that if we proceed with K=3, then we predict that test input belongs to class B, and if we continue with K=7, then we predict that test input belongs to class A.
Data scientists usually choose K as an odd number if the number of classes is 2 and another simple approach to select k is set k=sqrt(n). Similarly, you can choose the minimum value of K, find its prediction accuracy, and keep on increasing the value of K. K value with highest accuracy can be used as K value for rest of the prediction process.
KNN USING SCIKIT-LEARN
The example below demonstrates KNN implementation on the iris dataset using the scikit-learn library where the iris dataset has petal length, width and sepal length, width with species class/label. Our task is to build a KNN model based on sepal and petal measurements which classify the new species.
Step 1: Import the downloaded data and check its features.
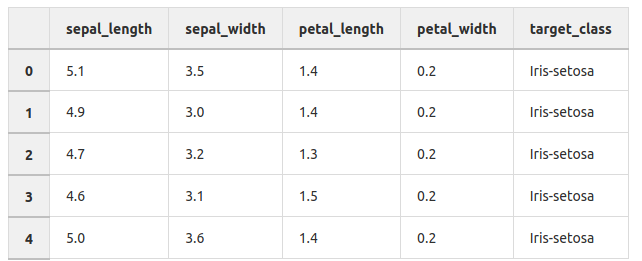
The Iris Dataset contains four features (length and width of sepals and petals) of 50 samples of three species of Iris (Iris setosa, Iris virginica, and Iris versicolor). Here, target_class is in a categorical form that can not be handled by machine learning algorithms like KNN. So feature and response should be numeric i.e. NumPy arrays which have a specific shape. For this, we have implemented a LabelEncoder for target_class which are encoded as 0 for iris_setosa, 1 for iris_versicolor, and 2 for iris_verginica.
Step 2: Split the data into train set and test set and train the KNN model
It is not an optimal approach for training and testing on the same data, so we need to divide the data into two parts, the training set and testing test. For this function called ‘train_test_split’ provided by Sklearn helps to split the data where the parameter like ‘test_size’ split the percentage of train data and test data.
‘Random_state’ is another parameter which helps to give the same result every time when we run our model means to split the data, in the same way, every time. As we are training and testing on various datasets, the subsequent quality of the tests should be a stronger approximation of how well the model would do on unknown data.
Step 3: Import ‘KNeighborsClassifier’ class from Sklearn
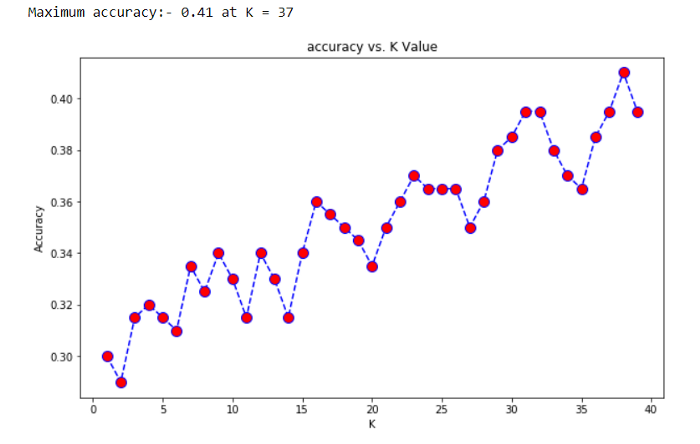
It is important to select the appropriate value of k, so we use a loop to fit and test the model for various values for K (for 1 – 25) and measure the test accuracy of the KNN. Detail about choosing K is provided in the above KNN from scratch section.

Step 4: Make Predictions
Now we are going to choose an appropriate value of K as 5 for our model. So this is going to be our final model which is going to make predictions.
PROS
- 1. KNN classifier algorithm is used to solve both regression, classification, and multi-classification problem
- 2. KNN classifier algorithms can adapt easily to changes in real-time inputs.
- 3. We do not have to follow any special requirements before applying KNN.
CONS
- 1. KNN performs well in a limited number of input variables. So, it’s really challenging to estimate the performance of new data as the number of variables increases. Thus, it is called the curse of dimensionality. In the modern scientific era, increasing quantities of data are being produced and collected. How, for target_class in machine learning, too much data can be a bad thing. At a certain level, additional features or dimensions will decrease the precision of a model, because more data has to be generalized. Thus, this is recognized as the “Curse of dimensionality”.
- 2. KNN requires data that is normalized and also the KNN algorithm cannot deal with the missing value problem.
- 3. The biggest problem with the KNN from scratch is finding the correct neighbor number.