
A blog to understand the working and intuition of Word2Vec. I have already covered the basics of NLP in my previous blog. If you haven’t gone through it, please find it here: NLP — Text Encoding: A Beginner’s Guide
Before we begin, please note down some points below.
- 1. I’ll refer to Word2Vec as w2v interchangeably.
- 2. We are not going into deep mathematical expressions or explanations of how W2V is designed. If you want a detailed walkthrough please refer the research paper here : https://arxiv.org/pdf/1301.3781.pdf
- 3. I’ll not be diving too deep into the deep learning aspects of it, as I want this blog to be an overview of the process i.e. an intuitive explanation.
Okay, now as we have the above pointers mentioned, let’s begin.
Text Encoding: Word2Vec
Word2Vec, as the name suggests, it is a word represented as a numeric vector. That’s all there is to understand. The main question is HOW? Well, that’s the tricky part. No worries, let me break down each and everything into sections and let’s understand them one by one.
Q1: What is w2v?
Word2vec is a shallow, two-layer Artificial Neural Network that processes text by converting them into numeric “vectorized” words. Its input is a large word corpus and output a vector space, usually hundreds of dimensions, with each unique word in the corpus represented with that vector space generated. It is used to reconstruct linguistic contexts of words into numbers. Word vectors are positioned in the vector space in such a way that the words that share common contexts are located in close proximity to one another in that multidimensional space, in layman terms the words that almost mean the same will be placed together. This model captures both syntactic and semantic similarities between the words.
Q2: How does the model capture semantic and syntactic similarities in word vectors?
Now there are a lot of things to explain here, let me try to keep it simple.
First let’s understand how we can get the semantic meaning between two words? How can one say that converting words into numbers which might have similar meaning could be represented close to each other? These are some obvious questions, for which we need to understand the output of the model and how to measure the closeness, then we will go ahead and understand how these vectors are created.
Let’s understand this with the help of an example:
Let us take 4 words: King, Queen, Man, Woman.
Now with our understanding we can obviously say that if I want to group similar words together I would rather do it as (King, Man) and (Queen, Woman). Also if I want to group opposite words together I would do it as (King, Queen) and (Man, Woman).
So if you look closely King is similar to Man and opposite to Queen and Queen is similar to Woman and opposite to King.
Now the main question is how is my vector representation going to capture such essence?
Is it even possible? Yes it is.
Let’s see how. For us to understand this i.e. the synonym and antonym preservation in words, we must understand how two vectors are compared and concluded whether they are similar or not mathematically. We need a comparison metric for two vectors with each other.
Generally we can divide similarity metrics into two different groups:
- Similarity Based Metrics:
- 1. Pearson’s correlation
- 2. Spearman’s correlation
- 3. Kendall’s Tau
- 4. Cosine similarity
- 5. Jaccard similarity
- Distance Based Metrics:
- 1. Euclidean distance
- 2. Manhattan distance
I will not go in depth of these metrics as we are not learning how to calculate those. To explain how these are to be understood: The closer two vectors are, they will have higher similarity value and less distance. The farther two vectors are, they will have lower similarity value and higher distance.
You can visualize this as
1 – Distance = Similarity or
1 – Similarity = Distance.
Similarity and Distance are inversely proportional to each other.
So now we understand how two vectors are compared for their similarity. So if we are to say w.r.t our example for King, Queen, Man and Woman, our common understanding would be that:
King’s word vector should have a high similarity score and lower distance with Man’s word vector and Queen’s word vector should have a high similarity score and lower distance with Woman’s word vector and vice versa.
To understand better this is how it is ought to look like:
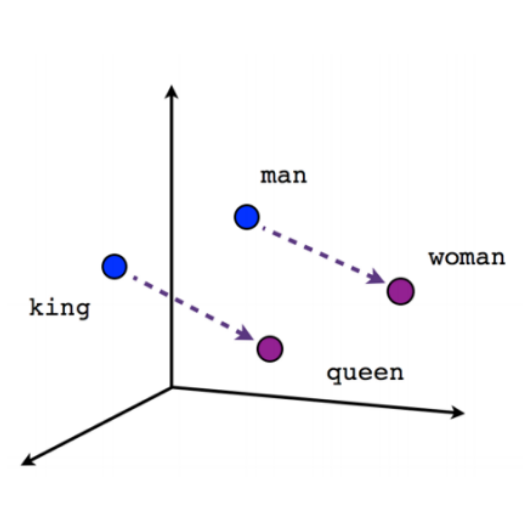
So we know how to measure synonyms and antonyms of words mathematically.
Now the main question arises is how do we achieve our target vectors?
Q3: How does w2v convert words to numeric vectors which conserve semantic meaning with them?
This can be achieved in two ways namely:
- 1. CBOW: try to predict target word using context words
- 2. Skip-Gram: try to predict context words using target word.
Let’s get on to it:
Before we start we need to understand certain keywords and why are they called as such:
- 1. Target Word: The word that is being predicted.
- 2. Context Word: Every other word in the sentence, apart from the target word.
- 3. Embedding Dimension: The number of vector dimensional space we want our words to be encoded into.
Understanding with Example:
Sentence: “The quick brown fox jumps over the lazy dog”
Let’s say we are trying to predict the word fox, then “fox” becomes our target word. And the rest of the remaining words become context words.
CBOW – Continuous Bag of Words, is a process where we try to predict the target word using the context words. Here we will teach our model to learn the word “fox” when we have the rest of the words as an input. CBOW tends to do well in smaller datasets.
Skip-Gram, is a process where we try to predict the context words with the help of the target word, exactly opposite of CBOW. Skip-gram tends to do better in larger datasets.
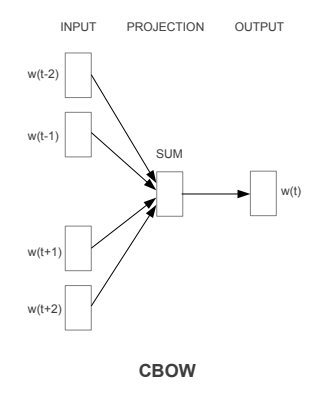
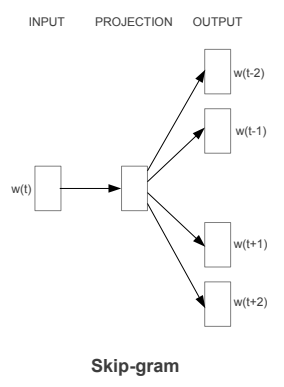
Here the input word is One-Hot encoded and sent into the model one by one, the hidden layer tries to predict the best probable word from the weights associated in the layer.
We will take our vector to be 300 dimension, so any word will be encoded into a 300 dimensional vector.
The last layer of our w2v model is a Softmax Classifier which tries to identify the best probable output.
The input to this network is a one-hot vector representing the input word, and the label is also a one-hot vector representing the target word, however, the network’s output is a probability distribution of target words, not necessarily a one-hot vector like the labels.
The rows of the hidden layer weight matrix are actually the word vectors (word embedding) we want!
The hidden layer operates as a lookup table. The output of the hidden layer is just the “word vector” for the input word.
Number of neurons in the Hidden layer should be the same as the embedding dimension we decide upon.
Let’s say we have 5 words in our corpus:
Sentence1 : Have a Good Day
Sentence2 : Have a Great Day
So no. of unique words? “have”, “a”, “good”, “great”, “day” = 5
Now, consider our target word for sentence1 is “good”
So if I feed my model the rest of the context words it should learn that “good” is the correct word it wants to predict for sentence1
Consider our target word for sentence2 is “great”
So if I feed my model the rest of the context words it should learn that “great” is the correct word it wants to predict for sentence2
If you look carefully both the context words for sentences are the same if we remove the target words, so how does the model accurately predict which one to predict where? Well actually it doesn’t matter because it will predict the most probable word in our case both “good” and “great” none of them is wrong. So now if you relate it to our synonym preservation here both the words “good” and “great” mean the same and are highly probable output for our given context words. Hence this is how our model learns the semantic meaning of words because in layman terms if I can use words interchangeably then only my target word changes and not context words and any two similar words having same synonym will be highly probable output for the context words we feed the model and will have almost similar numerical values as one another. If they have almost similar numerical values they ought to be close as vectors w.r.t similarity metrics and lesser distance. This is how the semantic meanings are captured.
Q4: How does the model work?
We will understand the model architecture in 4 steps
- 1. Data Preparation
- 2. Input
- 3. Hidden Layer
- 4. Output
These are the only structures of the model.
Data Preparation:
First let us understand how data is prepared for our model and how it is fed to it.
Consider the same sentence as above, ‘have a good day’. The model converts this sentence into word pairs in the form (context word, target word). The user will have to set the window size. If the window for the context word is 2 then the word pairs would look like this: ([have, good], a), ([a, day], good). With these word pairs, the model tries to predict the target word considering the context words.
Input:
The input of these models are nothing but a large one-hot encoded vector.
Let’s understand with examples:
Consider we have 10000 unique words in our data corpus, and we want our embedding dimension to be a 300 dimensional vector.
So our input will be a vector with 10000 dimensions with all the other words as 0 while the context word is kept as 1. The dimension of our input vector is 1 x 10000.
Hidden Layer:
The hidden layer is nothing but a weight matrix with all the words encoded with 300 dimensions randomly at the beginning. Then we train our model to adjust these weight values so that the model predicts better with each training step.
Now the Hidden layer has neurons exactly equal to the number of embedding dimensions we choose i.e. 300
So the dimension of our weight matrix is 10000 x 300.
Output Layer:
The output layer is nothing but a softmax layer which uses probability values to predict the results amongst the 10000 vectors we have. The dimension of our output vector becomes 1 x 300.
Now, Let us try to understand the mathematics happening w.r.t dimension,
Input: 1 x 10000
Hidden Layer: 10000 x 300
Output = Softmax( Input x Hidden Layer ) (matrix multiplication) = 1 x n * n x dim = 1 x dim = 1 x 300
The above architecture I just explained is the architecture of CBOW model, to understand Skip-gram we just have to reverse the order and instead of inputting the context word and figuring out the target words, we now input the target words and try to figure out the context words, CBOW is like multiple inputs one output, Skip-gram is like one input and multiple outputs.
In Skip-gram we can define how many context words we want to predict and accordingly we can create the input output pairs.
For example: ‘have a good day’
If we set the window size as 2 then the training pairs would be;
Target word: good
Context words: have, a, day
(good, have)
(good, a)
(good, day)
And hence the model learns and tries to predict words close to the target word.
Q5: What is the purpose of converting words into vectors?
These word vectors are now well equipped with syntactic and semantic meaning embedded into them hence they can be perfectly used as an input to any other complex NLP programs where we want to understand complex human conversations or context of languages.
W2V itself is a Neural Network but rather it works in a feature engineering layer before dealing with NLP related applications.
Implementation:
We will not learn how to implement the w2v model from scratch as we already have Gensim library to take care of, if you have your own specific domain oriented data corpus.
Or if you are working on general English language text data then i would recommend you to look into GloveVectors which are created by Stanford from billions of Wikipedia, Twitter or Common Crawl texts.
Conclusion:
We now have a better understanding of word embedding and are familiar with the concepts of Word2Vec. We understand the difference between Skip-Gram and CBOW. We also have intuition into how the word embedding are created and that the Hidden Layer is a giant lookup table for the word embedding. Also we have a gist of understanding how semantic and syntactic meanings are captured. Word embedding contain the potential of being very useful, even fundamental to many NLP tasks, not only traditional text, but also genes, programming languages, and other types of languages.
Next time we will look into BeRT encodings for text, till then Happy Learning!


