
Today, we will discuss Performance Metrics; this time, it will be Regression model metrics. As in my previous blog, we have discussed Classification Metrics; this time, it is Regression. We are going to talk about the five most widely used Regression metrics:
Let’s understand one thing first, and that is the Difference between Classification and Regression:


What is an Error?
In machine learning, an error refers to the difference between the predicted output of a model and the actual target or ground truth value. It indicates how far off the model’s predictions are from the correct answers. Errors are essential for assessing the performance and quality of a machine-learning model. They help us understand how well the model generalizes to new, unseen data.
There are several types of errors in machine learning:
1. Training Error: This error occurs when a model is evaluated on the same data it was trained on. It shows how well the model fits the training data but doesn’t necessarily reflect how well it will perform on new, unseen data.
2. Validation Error: During training, it’s common to set aside a portion of the data as a validation set to monitor the model’s performance on data it hasn’t seen before. The validation error is the error calculated on this validation set. It helps in tuning hyperparameters and selecting the best model.
3. Test Error: Once the model is finalized, it is evaluated on a separate dataset called the test set that it has never encountered during training or validation. The test error gives a more accurate representation of the model’s generalization performance.
4. Generalization Error: This refers to how well a trained model can perform on new, unseen data. A model with low generalization error can make accurate predictions on a wide range of inputs.
5. Bias Error: Bias error, also known as underfitting, occurs when a model is too simplistic to capture the underlying patterns in the data, resulting in poor performance on training and test data.
6. Variance Error: Variance error, also known as overfitting, happens when a model is too complex, and it learns to fit the noise in the training data rather than the actual underlying patterns. This leads to excellent performance on the training data but poor performance on test data.
7. Irreducible Error: Improving the model cannot reduce this error. The inherent noise in the data or unpredictable factors affects the relationship between inputs and outputs.
8. Mean Squared Error (MSE): A commonly used error metric calculates the average squared difference between predicted and actual values. It’s often used for regression problems.
9. Cross-Entropy Loss: This loss function is often used for classification problems. It measures the dissimilarity between the predicted class probabilities and the true class probabilities.
10. Misclassification Error: Specifically used in classification tasks, this error measures how many instances were incorrectly classified by the model.
Managing and understanding these various types of errors is crucial for building effective and reliable machine-learning models. The goal is to find the right balance between bias and variance, leading to a model that generalizes well to new data while avoiding under and overfitting.
Any deviation from the actual value is an error.
Error = Y (actual) – Y (predicted)
So, keeping this in mind, we have understood the requirement of the metrics, let’s deep dive into the methods we can use to find ways to understand our model’s performance.
Mean Squared Error (MSE)
Let’s try to break down the name, it says Mean, it says Squared, and it says Error. We know what an Error is; from the above explanation, we know what a square is. We square the Error, and then we know what the Mean is. So we take the mean of all the errors squared and added.
The first question that should arise is, why are we doing a Square? Why can we not take the error directly?
Take the height example; my model predicted 167cm, whereas my actual value is 163cm, so the deviation is +5cm. Let’s take another example where my predicted height is 158cm, and my actual height is 163cm. Now, my model made a mistake of -5cm.
Now let’s find the Mean Error for 2 points, so the calculation states [+5 + (-5)]/2 = 0
This shows that my model has 0 errors, but is that true? No right? So to avoid such problems, we have to take a square to eliminate the Sign of the error.
So let’s see the formulation of this Metric:
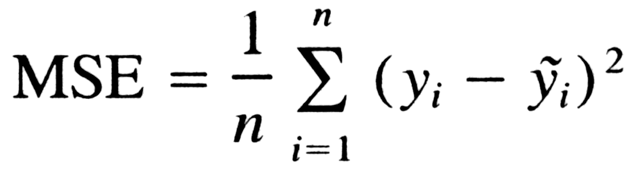
Where,
-> n = total number of data points
-> Yi = actual value
-> Ŷi = predicted value
Root Mean Squared Error (RMSE)
Now as we all understood what MSE is, it is pretty much obvious that taking root of the equation will give us RMSE. Let’s see the formula first.

Where,
-> n = total number of data points
-> Yi = actual value
-> Ŷi = predicted value
Now, the question is, if we already have the MSE, why do we require RMSE?
Let’s try to understand it with an example. Take the above example of the 2 data points and calculate MSE and RMSE for them,
MSE = [(5)2 + (-5)2]/2 = 50/2 = 25
RMSE = Sqrt(MSE) = (25)0.5 = 5
Now, you tell among these values which one is more accurate and relevant to the actual error of the model?
RMSE right? So, in actual Squaring off, the values increase exponentially. While not taking root might affect our understanding of where my model is actually making mistakes.
Mean Absolute Error (MAE)
Now, I am sure you might have thought about this, why squaring? Why not just take the Absolute value? here we have it. Everything stays the same, the only difference is, that we take the Absolute value of our error, and this also takes care of the sign issues we had earlier. So, let’s look into the formula :

Where,
-> N = total number of data points
-> Yi = actual value
-> Ŷi = predicted value
MAE VS RMSE
Let’s understand that MAE and RMSE can be used together to diagnose the variation in the errors in a set of forecasts. RMSE will always be larger or equal to the MAE. The greater the difference between them, the greater the variance in the individual errors in the sample. If the RMSE=MAE, then all the errors are of the same magnitude.
- Errors [2, -3, 5, 120, -116, 197]
- RMSE = 115.5
- MAE = 88.6
If we see the difference, RMSE has a higher value than MAE, which states that RMSE gives more importance to higher error due to squaring the values.
Mean Absolute Percentage Error (MAPE)
It is kind of similar to MAE, but the difference is: that we take the percentage error and not the absolute value. Let’s see the formulation:
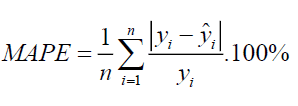
Where,
-> N = total number of data points
-> Yi = actual value
-> Ŷi = predicted value
MAPE represents the percentage error, and therefore it’s not relative to the size of the numbers in the data itself, whereas any other performance metrics in the regression model.
R² or Coefficient of Determination
It is the Ratio of the MSE (Prediction Error) and Baseline Variance of the target Variable; here baseline is the deviation of our Y values from the Mean value.
The metric helps us to compare our current model with constant baseline value (i.e., mean) and tells us how much our model is better. R2 is always less than 1, and it doesn’t matter how large or small the errors are; R2 is always less than 1. Let’s See the Formulation:

Conclusion:
These regression evaluation metrics serve distinct roles in assessing the performance of predictive models. RMSE and MSE are valuable for quantifying the magnitude of errors between predicted and actual values, which is crucial when precision matters and large errors should be penalized. MAE, on the other hand, offers an equally weighted measure of error magnitude, often preferred when outliers or extreme errors are of concern. MAPE finds its application in forecasting, where expressing errors as percentages relative to actual values aids in understanding prediction accuracy. R-squared provides insights into how well the model captures the variance in the data, serving as an indicator of the model’s explanatory power, though it must be interpreted judiciously considering potential model complexity and overfitting. The choice of metric depends on the specific objectives and characteristics of the regression problem at hand.


2 Comments on “Performance Metrics: Regression Model”