
Before starting tutorials on machine learning, we came with an idea of providing a brief definition of key terms used in Machine Learning. These key terms will be regularly used in our coming tutorials on machine learning from scratch and will also be used in further higher courses. So, let’s start with the term Machine Learning:
MACHINE LEARNING
Machine learning is the study of computer algorithms that comprises algorithms and statistical models that allow computer programs to improve through experience automatically. It is the science of getting computers to act by feeding them data and letting them learn a few tricks without being explicitly programmed.
TYPES OF MACHINE LEARNING
Do you want to know about supervised, unsupervised and reinforcement learning ? Read More
CLASSIFICATION
Classification is a fundamental concept in machine learning and data analysis aimed at categorizing input data points into predefined classes or categories based on their inherent characteristics. It involves the creation of predictive models that learn patterns and relationships from labeled training data, enabling them to accurately assign new, unlabeled data to the appropriate classes. Classification methods span various techniques such as decision trees, support vector machines, logistic regression, and neural networks, each with its unique strengths and limitations. Applications of classification are diverse, encompassing image recognition, spam email detection, medical diagnosis, sentiment analysis, and more, making it a pivotal tool for organizing, interpreting, and deriving insights from complex data sets.
REGRESSION
Regression constitutes a vital aspect of machine learning, where the focus lies on predicting continuous numerical values. It falls within the realm of supervised learning and serves to answer queries such as “How much?” or “How many?” by establishing correlations and associations among different data types; unlike classification, which assigns discrete labels, regression endeavors to unveil a functional connection between input variables and continuous output, enabling the prediction of numeric outcomes. Linear Regression, a prevalent regression algorithm, seeks the optimal straight-line fit that minimizes the disparity between predicted and actual values. Beyond Linear Regression, more advanced techniques like Polynomial Regression, Ridge Regression, Lasso Regression, and Support Vector Regression cater to intricate data relationships, contributing to a comprehensive toolkit for comprehending and modeling continuous data phenomena.
CLUSTERING
A cluster is characterized as a collection of data points sharing similarities or connections within the group while being distinct from data points in other clusters. This process, referred to as clustering, aims to organize data into these cohesive clusters. The primary objective of clustering is to identify inherent patterns of grouping within a dataset lacking predefined labels. Clustering falls under the category of unsupervised learning, as it operates without the need for labeled data to guide the process. Through clustering, datasets can be partitioned into meaningful segments, aiding in data exploration, pattern recognition, and the discovery of underlying structures, all of which contribute to a deeper understanding of complex datasets.
HISTORY OF ARTIFICIAL INTELLIGENCE
The beginning of modern AI started when the term “Artificial Intelligence” was coined in 1956, at a conference at Dartmouth College, in Hanover. Read More…..
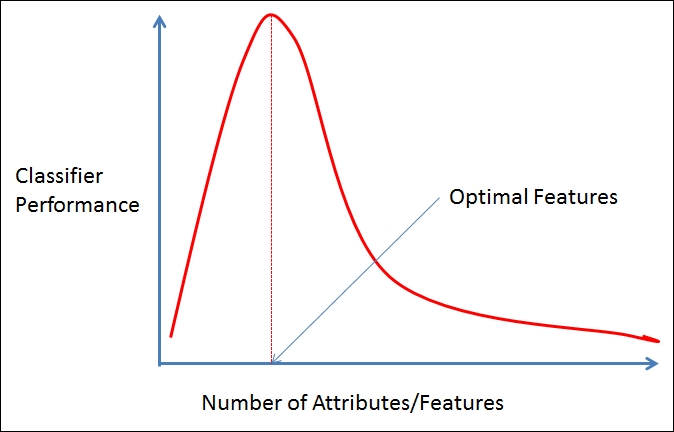
DIMENSIONALITY
The dimensionality of a dataset refers to the count of attributes or features associated with the objects in that dataset. When a dataset contains a high number of attributes, it can become challenging to effectively analyze it, a phenomenon often termed as the “curse of dimensionality.”
CURSE OF DIMENSIONALITY
Data analysis becomes difficult as the dimensionality of the data set increases. As dimensionality increases, the data becomes increasingly sparse in its space.
- 1. For classification, there will not be enough data objects to create a model that reliably assigns a class to all possible objects.
- 2. For clustering, the density and distance between points, which are critical for clustering, become less meaningful.
UNDERFITTING
Underfitting in machine learning arises when a model oversimplifies the data, leading to poor performance in capturing its inherent complexities. For instance, envision predicting a student’s performance based solely on the number of hours they study each day. If the relationship between study time, sleep, and social activities is more intricate, a linear model might underfit by failing to account for these nuanced interactions.
Underfitting can also stem from a scarcity of data during model training. Imagine training a speech recognition system with just a handful of spoken words per person. Such a model might struggle to accurately transcribe new voices due to its limited exposure to diverse speech patterns. In both cases, addressing underfitting might involve using more advanced models or amassing more comprehensive datasets to capture the multifaceted nature of the data better.
OVERFITTING
When a model is trained using lots of data, it might start paying too much attention to all the little details, even the mistakes and random stuff in the data. This can lead to a problem called overfitting, where the model is great at the training data but stumbles when faced with new data. This is especially likely when using certain fancy techniques that can mold themselves too closely to the training data.
But there’s a trick called cross-validation that helps fix this. It lets us fine-tune the model’s settings using only the original training data and keeps the test data as a secret test to see how well the final model does on brand-new data. This way, we make sure the model doesn’t get too caught up in the noise from the training data and can still do a good job predicting things it hasn’t seen before.

Many key terms are used in machine learning other than those described above. Other key terms will be discussed later in the tutorial.


Wohh exactly what I was searching for, regards for posting.
This post presents clear idea in support
of the new people of blogging, that genuinely how to do
blogging. adreamoftrains best web hosting 2020
You have made some decent points there. I
checked on the net for more info about the issue and found
most people will go along with your views on this site.