
In the project Image Captioning using deep learning, is the process of generation of textual description of an image and converting into speech using TTS. We introduce a synthesized audio output generator which localize and describe objects, attributes, and relationship in an image, in a natural language form. This also includes high quality rich caption generation with respect to human judgments, out-of-domain data handling, and low latency required in many applications.
Our applicationdeveloped in Flutter captures image frames from the live video stream or simply an image from the device and describe the context of the objects in the image with their description in Devanagari and deliver the audio output.
Keywords : Text to speech, Image Captioning, AI vision camera
INTRODUCTION
Every day, we encounter a large number of images from various sources such as the internet, news articles, document diagrams and advertisements. These sources contain images that viewers would have to interpret themselves. Most images do not have a description, but the human can largely understand them without their detailed captions. However, machine needs to interpret some form of image captions if humans need automatic image captions from it.
1.1 Image Captioning
Ever since researchers started working on object recognition in images, it became clear that only providing the names of the objects recognized does not make such a good impression as a full human-like description. As long as machines do not think, talk, and behave like humans, natural language descriptions will remain a challenge to be solved. There have been many variations and combinations of different techniques since 2014.
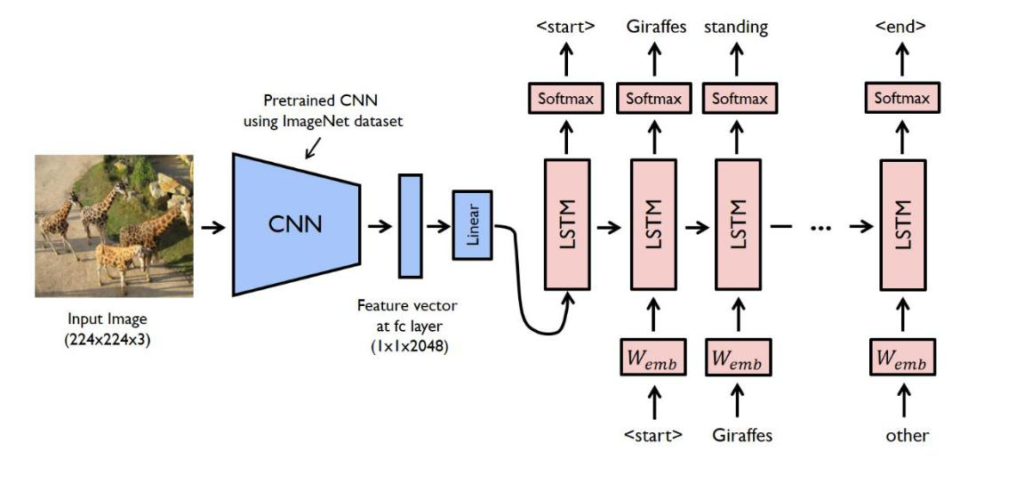
The leading approaches can be categorized into two streams. One stream takes an end-to-end, encoder-decoder framework adopted from machine translation. For instance, used a CNN to extract high level image features and then fed them into a LSTM to generate caption went one step further by introducing the attention mechanism. The other stream applies a compositional framework. For example, divided the caption generation into several parts: word detector by a CNN, caption candidates’ generation by a maximum entropy model, and sentence re-ranking by a deep multimodal semantic model.
1.2 Text to Speech (TTS)
A text-to-speech (TTS) system converts normal language text into speech. First, it converts raw text containing symbols like numbers and abbreviations into the equivalent of written-out words and divides and marks the text into prosodic units like phrases, clauses, and sentences. Then the synthesizer converts the symbolic linguistic representation into sound.
Text to Speech has long been a vital assistive technology tool and its application in this area is significant and widespread. It allows environmental barriers to be removed for people with a wide range of disabilities. The longest application has been in the use of screen readers for people with visual impairment, but text-to-speech systems are now commonly used by people with dyslexia and other reading difficulties as well as by pre-literate children. They are also frequently employed to aid those with severe speech impairment usually through a dedicated voice output communication aid.
1.3 Flutter
Flutter is an open-source UI software development kit created by Google. It is used to develop applications for Android, iOS, Windows, Mac, Linux, Google Fuchsia and the web. Flutter apps are written in the Dart language and make use of many of the language’s more advanced features. On Windows, macOS and Linux via the semi-official Flutter Desktop Embedding project, Flutter runs in the Dart virtual machine which features a just-in-time execution engine. While writing and debugging an app, Flutter uses Just in Time compilation, allowing for “hot reload”, with which modifications to source files can be injected into a running application. Flutter extends this with support for stateful hot reload, where in most cases changes to source code can be reflected immediately in the running app without requiring a restart or any loss of state. This feature as implemented in Flutter has received widespread praise. UI design in Flutter involves using composition to assemble / create “Widgets” from other Widgets. The trick to understanding this is to realize that any tree of components (Widgets) that is assembled under a single build () method is also referred to as a single Widget. This is because those smaller Widgets are also made up of even smaller Widgets, and each has a build () method of its own. This is how Flutter makes use of Composition.
OBJECTIVE
Objective of our system is:
- To develop an offline mobile application that generates synthesized audio output of the image description.
System Requirements
Functional Requirements
- Localize and describe salient regions in images
- Convert the image description in speech using TTS
Non-Functional Requirements
- 24×7 availability and should be efficient
- Better software development to get better performance
- Flexible service based architecture for future extension
Hardware Requirements
- Smartphone
Software Requirements
- Python
- Open CV
- Operating System: Windows/Linux
- Flutter
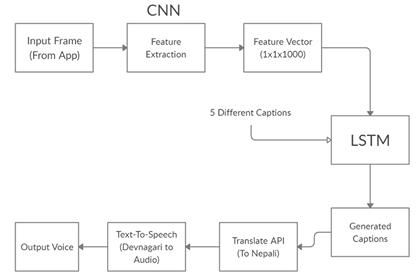
Algorithm Used
- CNN
- LSTM
EXPECTED OUTPUT
The final application designed in Flutter should look something like this. The first screen shows the view finder where the user can capture the image. After being processed the description of the image is as shown in second screen.

REFERENCES
- K. Tran, L. Zhang, J. Sun. “Rich Image Captioning in the Wild”. Microsoft Research.2016
- J. Johnson, A. Karpathy, L. “Dense Cap: Fully Convolutional Localization Networks for Dense Captioning”. Department of Computer Science, Stanford University. February 2016
- Z. Hossain, F. Sohel, H. Laga. “A Comprehensive Survey of Deep Learning for Image Captioning”. Murdoch University, Australia. October 2018
- A. Karpathy, Fei-Fei Li. “Automated Image Captioning with ConvNets and Recurrent Nets”. Stanford University,2013
- O. Karaali, G. Corrigan, I. Gerson, and N. Massey. “TEXT-TO-SPEECH CONVERSION WITH NEURAL NETWORKS: A RECURRENT TDNN APPROACH”. Rhodes, Greece. November 1998.
- Moses Soh. “Learning CNN-LSTM Architectures for Image Caption Generation”. Department of Computer Science Stanford University.2010
- Vinyals O, Toshev A, Bengio S, Erhan D. Show and tell: Lessons learned from the 2015 mscoco image captioning challenge. IEEE transactions on pattern analysis and machine intelligence 2017;39(4):652–63.
- Mori Y, Takahashi H, Oka R. Image-to-word transformation based on dividing and vector quantizing images with words. In: First International Workshop on Multimedia Intelligent Storage and Retrieval Management. Citeseer; 1999:1–9.
- LeCun Y, Bengio Y, Hinton G. Deep learning. nature 2015;521(7553):436.
- Hochreiter S, Schmidhuber J. Long short-term memory. Neural computation 1997;9(8):1735–80.
- Cho K, Van Merrie¨nboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, Bengio Y. Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:14061078 2014.
This much for todays project Image Captioning using deep learning, is the process of generation of textual description of an image and converting into speech using TTS. We will see you in the next tutorial. Till then Good Bye and Happy new year!!



Do you have a android app ?