
GAN, from the field of unsupervised learning, was first reported on in 2014 from Ian Goodfellow and others in Yoshua Bengio’s lab. Generative Adversarial Network is composed of two neural networks, a generator G and a discriminator D.
Generator:
Generator is the first Neural Network of GAN which tries to generate fake data similar to the real one from the randomly generated noise which is called G(z). Generator is used for generating fake images. In each iteration, generator learns to create an image similar to the real image so that discriminator can’t distinguish it as fake anymore.
Discriminator:
The data generated by Generator is then passed into Discriminator. Discriminator model is used to distinguish whether the generated data is real or fake. Training continues until the Generator succeeds in creating realistic data or when Discriminator can’t distinguish it as a fake image.
MINMAX GAME BY G & D

Above is the loss function of GAN. The loss/error function used maximizes the function D(x), and it also minimizes D(G(z)) where x is the real image, and G(z) is the generated image.
Let’s look above loss function from Generator perspective: since x is the actual image, we want D(x) be 1, and Generator tries to increase the value of D(G(z)) i.e. probability of being real. The training procedure for G is to maximize the probability of D making a mistake by generating data as realistic as possible.
Let’s look above loss function from Discriminator perspective: since x is the actual image, we want D(x) be 1, and Discriminator tries to decrease the value of D(G(z)) as 0 i.e fake image.
After training, the Generator and Discriminator will reach a point at which both cannot improve anymore. This is the state where the Generator produces more realistic images and Discriminator can’t distinguish it as fake.

GAN IMPLEMENTATION ON MNIST DATASET
In this tutorial, we’ll be building a generative adversarial network (GAN) trained on the MNIST dataset. The purpose of this tutorial is to learn how to create undistinguishable images of hand-written digits using GAN. Let’s start from the beginning by importing all the required libraries and by defining some hyper-parameters which is later used.
The above transformations are necessary to make the image compatible as an input to the neural network of the discriminator. Here, we will be using MNIST dataset consisting of 28×28 black and white images. Download the dataset here.
Now, we’ll be creating a class for Generator which contains architecture of the Generator and a class for Discriminator.

Above is the Binary Cross Entropy Loss (BCE Loss) function where y are named targets, v are the inputs, and w are the weights.
Discriminator loss
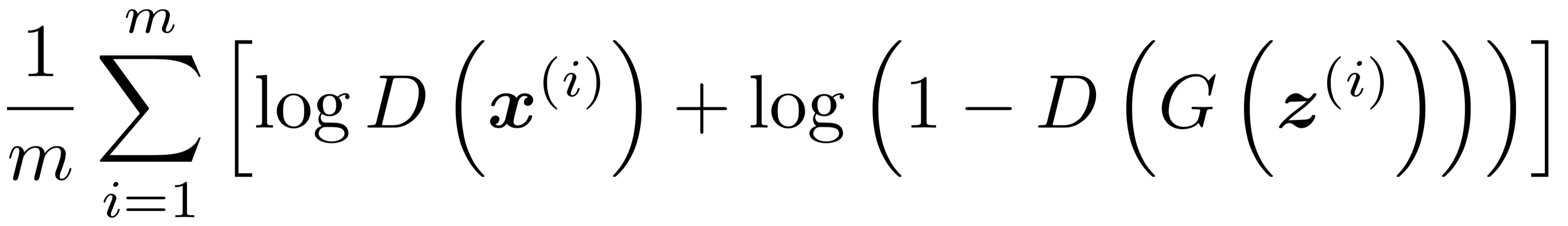
If we replace vᵢ = D(xᵢ) and yᵢ=1 ∀ i (for all i) in the BCE-Loss definition, we obtain the loss related to the real-images. Conversely, if we set vᵢ = D(G(zᵢ)) and yᵢ=0 ∀ i, we obtain the loss related to the fake-images. By summing up these two discriminator losses we obtain the total mini-batch loss for the Discriminator.
Generator Loss
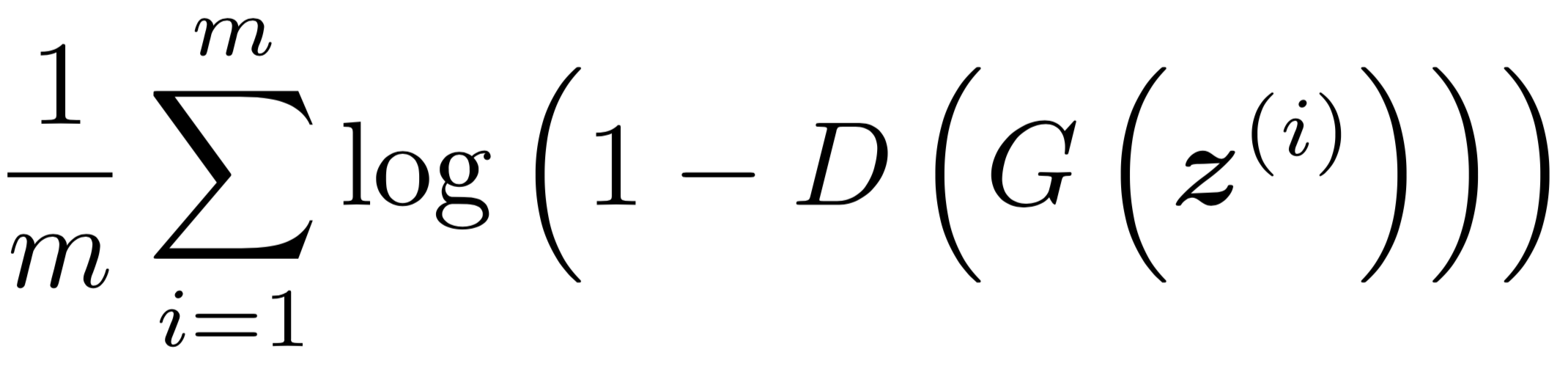
Rather than minimizing log(1- D(G(z))), training the Generator to maximize log D(G(z)) will provide much stronger gradients early in training. Similar to the Discriminator, if we set vᵢ = D(G(zᵢ)) and yᵢ=1 ∀ i, we obtain the desired loss to be minimized.
Results
First, we train Discriminator network using unsupervised learning so we don’t need any labels. We calculate the loss on real data and label it as 1. Next, we will calculate the loss on fake data(noise) coming from the generator network. Finally, we train Generator network by passing noise to it, and the result of output is then passed to discriminator to predict real or fake image. And after calculating the loss we back-propagate the generator network.
OUTPUT AT EPOCH 0 (PURE NOISE)

OUTPUT AT EPOCH 10

OUTPUT AT EPOCH 20




I just like the valuable info you provide in your articles.
I’ll bookmark your weblog and test once more here frequently.
I am moderately certain I will learn many new stuff right right here!
Good luck for the following! adreamoftrains best web hosting 2020
Very nice article, just what I wanted to find.
Thanks for any other informative blog. Where else could I get that type of info written in such an ideal method?
I have a project that I’m just now running on, and I’ve been at the glance out for such information.