
The Credit Card Fraud Detection project is used to identify whether a new transaction is fraudulent or not by modeling past credit card transactions with the knowledge of the ones that turned out to be fraud. We will use various predictive models to see how accurate they are in detecting whether a transaction is a normal payment or a fraud.
Classification techniques are the promising solutions to detect the fraud and non-fraud transactions. Unfortunately, in a certain condition, classification techniques do not perform well when it comes to huge numbers of differences in data distribution.
We are using the datasets provided by Kaggle. This data set includes all transactions recorded over the course of two days. As described in the dataset, the features are scaled and the names of the features are not shown due to privacy reasons.
The dataset consists of numerical values from the 28 ‘Principal Component Analysis (PCA)’ transformed features, namely V1 to V28. Furthermore, there is no metadata about the original features provided, so pre-analysis or feature study could not be done.
There are 284807 records. The only thing we know is that those columns that are unknown have been scaled already.
There are no “Null” values, so we don’t have to work on ways to replace values.
Most of the transactions are non-fraud. If we use this dataframe as the base for our predictive models and analysis we might get a lot of errors and our algorithms will probably overfit since it will “assume” that most transactions are not fraud. But we don’t want our model to assume, we want our model to detect patterns that give signs of fraud!
The data set is highly skewed, consisting of 492 frauds in a total of 284,807 observations. This resulted in only 0.172% fraud cases. This skewed set is justified by the low number of fraudulent transactions.
Now that we have the data, we are using only 3 parameters for now in training the model (Time, Amount, and Class).
The random forest is a supervised learning algorithm that randomly creates and merges multiple decision trees into one “forest.” The goal is not to rely on a single learning model, but rather a collection of decision models to improve accuracy.
The accuracy of Render forest is 0.9980513324672589.
TP = True Positive. Fraudulent transactions the model predicts as fraudulent.
TN = True Negative. Normal transactions the model predicts as normal.
FP = False Positive. Normal transactions the model predicts as fraudulent.
FN = False Negative. Fraudulent transactions the model predicts as normal.
Accuracy is the measure of correct predictions made by the model – that is, the ratio of fraud transactions classified as fraud and non-fraud classified as non-fraud to the total transactions in the test data.
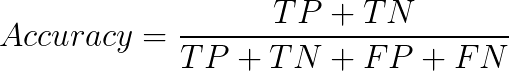
Lets use other Classification algorithms too!!!
The accuracy of Naive Bayes is 0.9982971103542713
The accuracy of Dummy Classifier is 0.9967171096520487
The accuracy of SVM is 0.9982971103542713
Since over 99% of our transactions are non-fraudulent, an algorithm that always predicts that the transaction is non-fraudulent would achieve an accuracy higher than 99%. Owing to such imbalance in data, an algorithm that does not do any feature analysis and predicts all the transactions as non-frauds will also achieve an accuracy of 99.829% (SVM). Therefore, accuracy is not a correct measure of efficiency in our case.
To create our balanced training data set, We calculated all of the fraudulent transactions in our data set . Then, We randomly selected the same number of non-fraudulent transactions and concatenated the two. There are 492 cases of fraud in our dataset so we can randomly get 492 cases of non-fraud to create our new sub dataframe.
Down-Sizing is method, closely related to the over-sampling method, that was considered in this category (rand_downsize) consists of eliminating, at random, elements of the over-sized class until it matches the size of the other class.
The accuracy of Render forest is 0.7766497461928934. Our classification models will not perform as accurate as previous because during under-sampling there is information loss as 492 non-fraud transaction were sampled from 284,315 non-fraud transaction.
Conclusion
Similarly, We can use various other model in credit card fraud detection. In this unevenly distributed data, we have used down sampling. We can also use Over sampling along with the models like encoder decoder, SMOTE for oversampling and so on.
This much for today. Will see you later with more informative project tutorial and codes. Keep loving us !!



It’s difficult to find experienced people on this topic, however, you seem like you
know what you’re talking about! Thanks
Hi! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up losing many months of hard work due to no backup.
Do you have any methods to stop hackers? adreamoftrains web
hosting